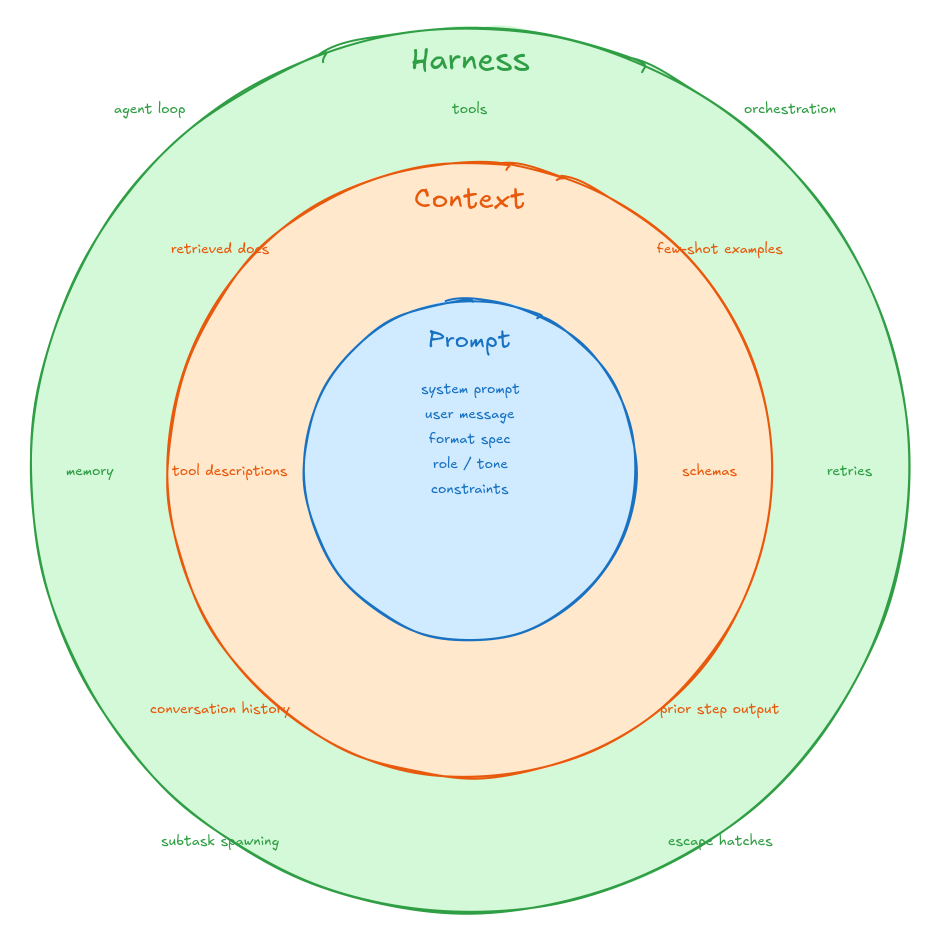
When an AI product produces good output, three things had to go right. When it produces bad output, the cause is almost always in one of those three things. The model itself, Claude or GPT or Gemini or whichever, is the most visible variable. It’s rarely the most consequential.
The three layers are the prompt, the context, and the harness. Each is a different kind of engineering work, and the distinction between them turns out to matter more than most teams realize. I’ll use Revarta, the AI interview prep app I’m building, to make each one concrete.
Prompt engineering
The prompt is the instruction itself: the system prompt, the user message, the format you want the model to return, the role you’re framing it in, the tone, the constraints. It’s the single most editable surface and the closest thing to a knob.
In Revarta, the prompt for a mock interview tells the model: you’re an interviewer for a Senior Product Manager role at a FAANG-scale company. Ask one question at a time. Evaluate the answer against this rubric. Don’t reveal the answer or hint at the right framework. Stay in character. Each of those rules is the result of a specific failure I watched the model make. Without “ask one question at a time,” it dumped three at once. Without “stay in character,” it drifted into coaching mode mid-interview. Every line in the prompt is a fence that took a real failure to put up.
A good prompt removes ambiguity. Most disappointing AI outputs are responses to disappointing prompts: instructions that left too much to interpretation, omitted the format, didn’t name the failure modes, or asked for two different things at once. Prompt engineering is the work of getting the instruction right.
Context engineering
The context is everything the model knows when it acts. The retrieved documents, the few-shot examples, the conversation history, the schema definitions, the tool descriptions, the user metadata, the output of prior steps. The prompt tells the model what to do. The context determines whether it has any chance of doing it well.
Before Revarta asks a single interview question, the model needs context: which role the candidate is targeting, which company, the candidate’s resume, prior interview history, the evaluation rubric for that role, the question bank for the topic. None of that lives in the prompt. It lives in the context window, retrieved and injected per call. Get it wrong and the model gives a system design question to a candidate prepping for product strategy. Worse, it evaluates the answer using the wrong rubric and tells the candidate they did well when they were off-target.
The model can only work with what it can see. Bad context produces confident wrong answers, because the model doesn’t know what it doesn’t know. Context engineering is the work of deciding what the model gets to see, in what form, at the moment of each call.
Harness engineering
The harness is the environment around the model. The agent loop, the tool surface, the orchestration, the memory strategy, the guardrails, the retry behavior, the way subtasks are spawned and resolved, the escape hatches when something goes wrong.
In Revarta, the harness is what makes a mock interview feel like an interview instead of a single API call. It decides when to ask a follow-up versus move on. It manages session state across questions. It detects when the candidate is stuck and offers to repeat the question. It catches and recovers when the model returns malformed JSON. It logs every turn for later review. The model is one piece of work in a longer loop, and the harness decides what work the model is being asked to do and how the answer gets used.
Harness engineering is the work of designing the system that wraps the model. The structure that turns a stateless call into a repeatable behavior.
These three layers don’t compete. They compose. A great prompt with no context fails because the model has nothing to ground its answer in. Great context with a weak harness fails because the model is being asked to do too much in too little structure. A great harness with a vague prompt fails because the model doesn’t know what good output looks like. Output quality is the product of all three, not the sum. Any one of them at zero zeros out the result.
This is also why model upgrades disappoint so often. A more capable model raises the ceiling on every layer at the same time, but it doesn’t, by itself, fix any of them. The same model produces inconsistent output in one product and excellent output in another, because the environment around the model is doing most of the work.
The lens is useful because it gives you somewhere specific to look. When something is off, the question stops being “is the model good enough?” and starts being “which layer is the problem in?” That’s a much more answerable question, and it points at a much more productive kind of work.